

Using Python & OpenCV to detect duplicate images
Published on Jun 26, 2020 by Sachin.
For a couple of days I was looking for an application that could help detect duplicate photos which got accumulated as a result of backup from Mobile phone, Cameras and other devices. Chances of coping the same set of photos happen especially after buying a large storage device and I want to backup all my photos from the old storage to the new storage device. I lazily don’t care about which set of photos were already copied previously thus end up copying the same images again. Another situation is when I take the time series snaps and never get time to select the most significant photo(s). This is huge wastage of disk space. Luckily, I came across this blog post by Adrian Rosebrock which tackles this issue.
I did few enhancements to the original script to keep the image with the highest resolution, pass the hashsize as an argument to have greater control over the detected images, implemented threading which is useful to scan large datasets.
Features
- View duplicate images: If -m/–move is not used.
- Preference to High resolution images (default).
- Accuracy: Use -s/–hashsize.
- Threading: Use -w/–workers.
- Save data set in JSON format: The script will overwrite exiting dataset.json.
- Packaging: Install using pip.
- Multiple data set: Able to specify multiple datasets.
Setup
Download the source code from GitLab/psachin/opencv and install the dependencies using,
pip install -r requirements.txt
Usage
Running the script with
-d/--datasetoption will not delete/move the duplicate image. Use-m/--moveto actually move the duplicate image to thedeleted/directory. The script will run with the default hashsize of 8 using one thread,1: python ./dup_detect_and_remove.py --dataset <PATH_TO_DATA> 2: 3: # Example: 4: python ./dup_detect_and_remove.py --dataset ~/Pictures/ 5: 6: # To move duplicate images to the 'deleted' directory, use, 7: python ./dup_detect_and_remove.py --dataset ~/Pictures/ --move
If the script still detects very similar images as duplicate, such as time series photos, try raising the hashsize using
-s/--hashsizeoption,python ./dup_detect_and_remove.py --dataset <PATH_TO_DATA> --hashsize 10
Try combination of
-s/--hashsize&-w/--workersfor various workloads. See what works for you,# Example: python ./dup_detect_and_remove.py --dataset <PATH_TO_DATA> --hashsize 10 --worker 4
Screenshots
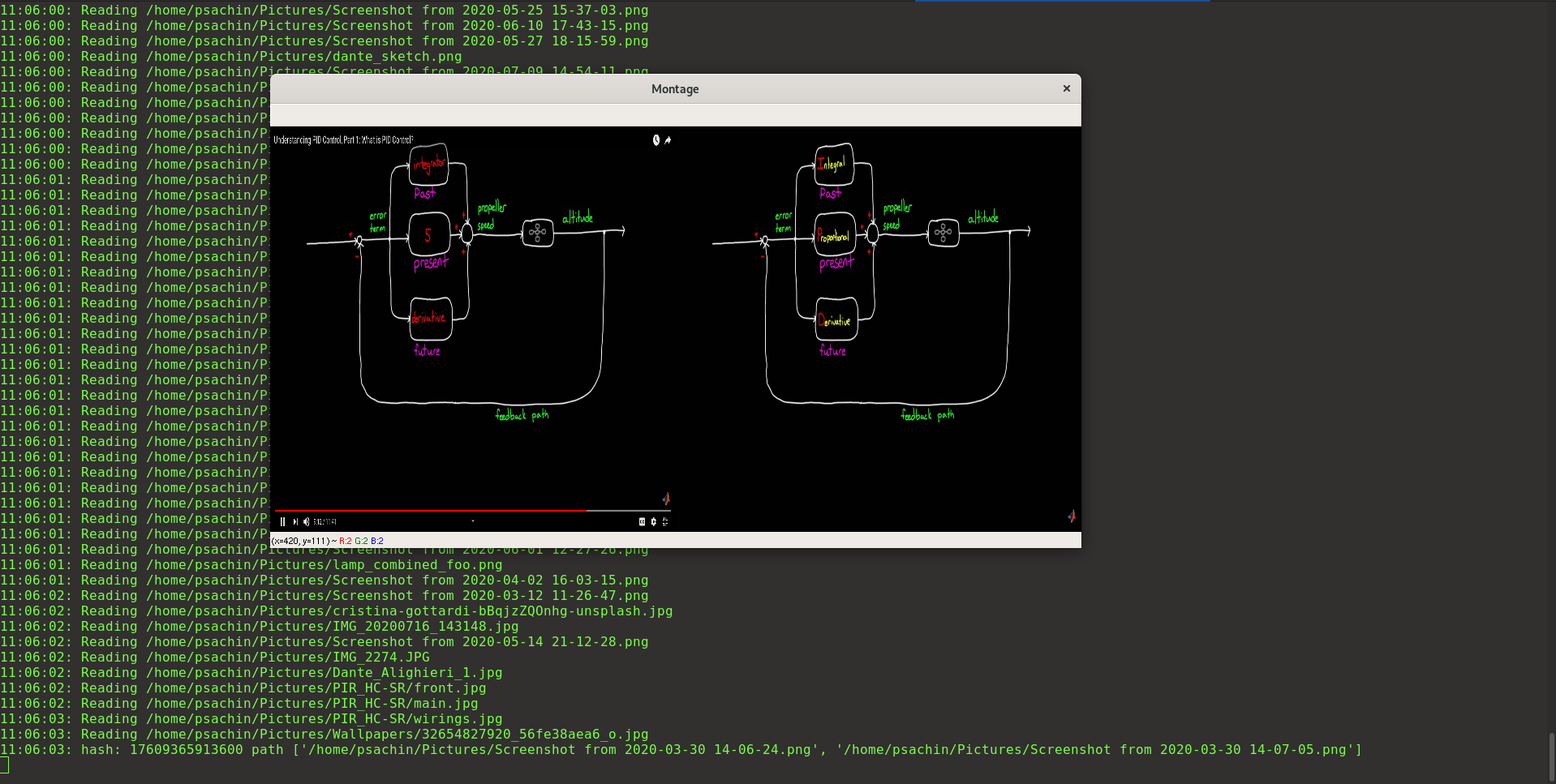
Figure 1: Take a closer look…above two photos are not duplicate. Raising the hashsize value will eliminate this problem.
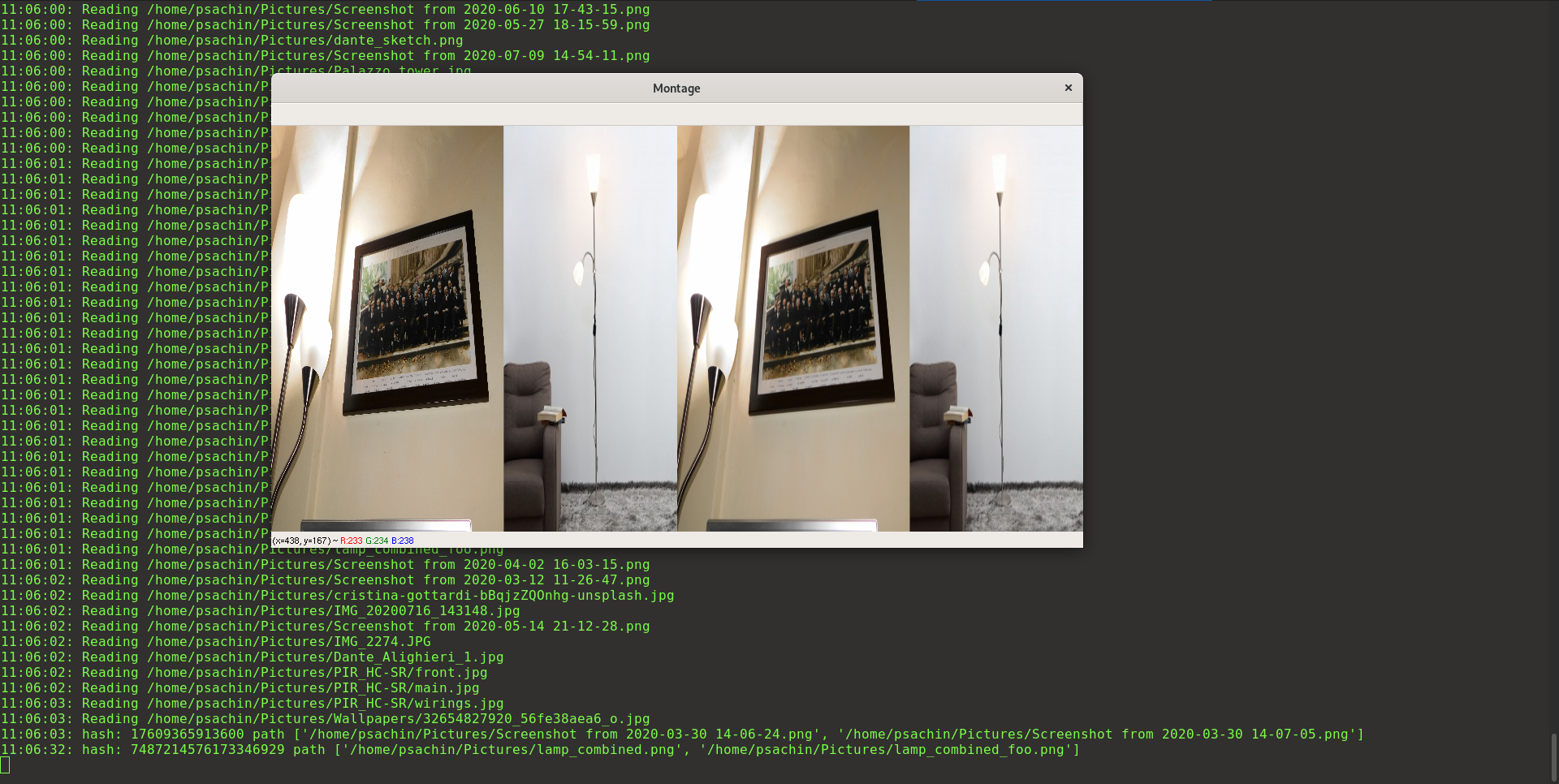
Figure 2: The two images are duplicate except one has the lower resolution. Raising the hashsize value will not detect these images as duplicate, but we don’t really want to do that.
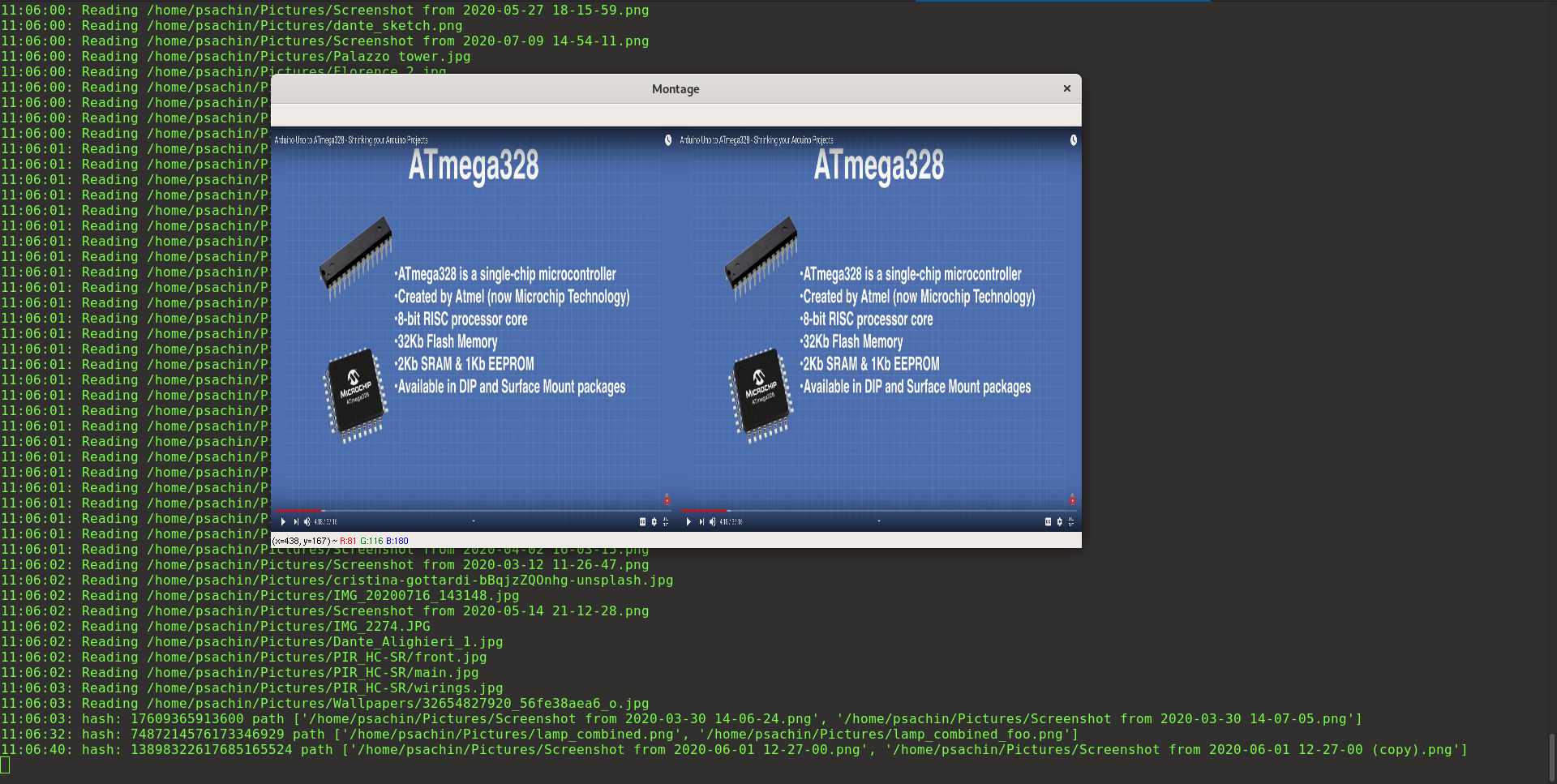
Figure 3: The two images are exact copies. This will be detected anyways.
Conclusion
- I have tested the script with various combination of threads & hashsize on ~70GB of data and was very satisfied with the result.
- The script has no issue running over NFS data or an external storage.